Mondo Robotics、香港科技大学【端到端具身智能框架】
客户名称:Mondo Robotics、香港科技大学
应用类型:仿真模拟
项目时间:2026年3月
应用产品:人形机器人G1
应用类型:仿真模拟
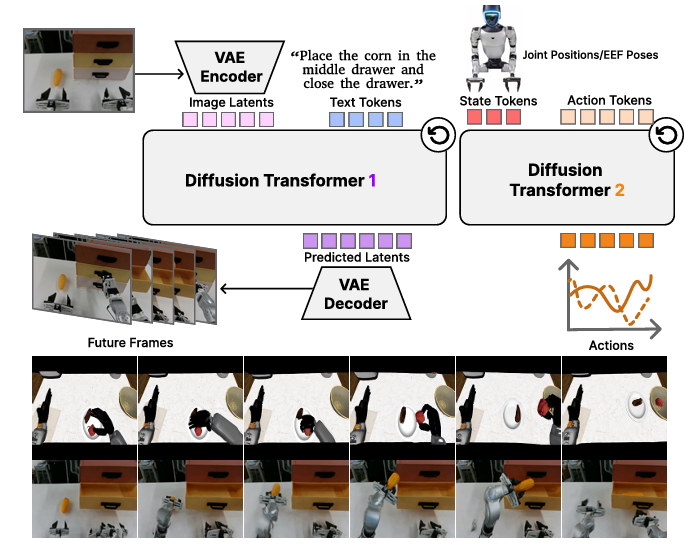
项目概述:在具身智能领域,视觉 - 语言 - 动作(VLA)模型虽能迁移语义先验,但受限于静态图像 - text 预训练,难以捕捉物理动态;而视频生成模型虽蕴含丰富时空与物理信息,却未能与动作控制实现深度融合,导致泛化性与控制精度难以兼顾。为此,研究团队提出 DiT4DiT 框架,通过端到端联合训练视频扩散 Transformer(Video DiT)与动作扩散 Transformer(Action DiT),以视频生成过程中的中间去噪特征为桥梁,将动态生成能力与精确控制需求紧密耦合,在仿真与真实环境中均实现 state-of-the-art(SOTA)性能,为构建可扩展、高泛化的具身智能体提供了全新架构范式。项目地址:https://dit4dit.github.io/
项目成果:
DiT4DiT 构建了 “生成式动态建模 + 精确动作控制” 的统一架构,首次实现视频扩散与动作扩散的端到端联合训练,以中间去噪特征为桥接,解决了动态生成与动作控制的协同难题,为具身智能提供了全新的 “动态感知 - 控制生成” 链路,通过视频模型内置的物理动态先验,大幅降低对动作数据的依赖,实现对 unseen 物体、场景变化的零样本泛化,推动具身智能体从 “特定任务适配” 向 “开放环境通用” 跨越。




 Donghu Robot Laboratory, 2nd Floor, Baogu Innovation and Entrepreneurship Center,Wuhan City,Hubei Province,China
Tel:027-87522899,027-87522877
Donghu Robot Laboratory, 2nd Floor, Baogu Innovation and Entrepreneurship Center,Wuhan City,Hubei Province,China
Tel:027-87522899,027-87522877 

































